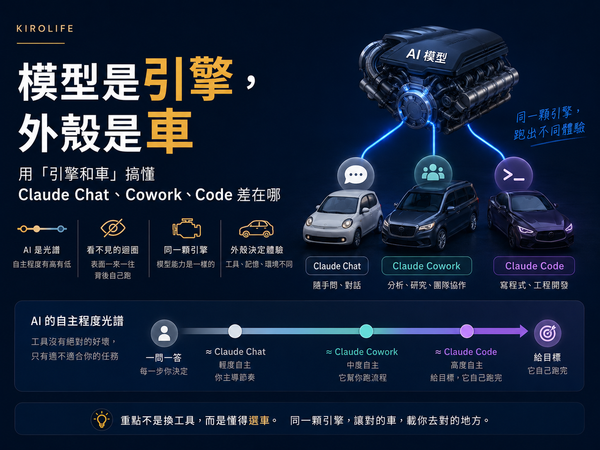
資料工程的 CLAUDE.md 踩坑筆記:規則越多,AI 越不守規矩
用 Claude Code 兩個月後我學到的事:CLAUDE.md 越長 AI 越容易忽略指令。把規則分成硬規則與軟判斷,硬規則外包給機制,軟判斷才留在文件。附我實際在用的範本。


用 AI 寫 code 的人都撞過同一面牆:每開一個新對話,它就失憶一次。你專案的規矩、命名慣例、踩過的雷,全部得從頭再講一遍。
有人的解法是自己存一坨 prompt,每次開工複製貼上。但這招撐不久——貼上麻煩;規矩改了還得回頭改那坨;最糟的是它只會越長越肥,肥到你自己都懶得貼。
CLAUDE.md 就是來解決這件事的:把那坨 prompt 變成一份常駐、版控、改一次就生效的指令,AI 每次開工自動讀進去。而且它不只一個檔——root CLAUDE.md 底下還掛著一層 .claude/rules/ 分層規範(碰到對應檔案才載入),整套合起來,才是給 AI 的協作規範;下面我說「CLAUDE.md」,多半就指這一整套。
我做數據這行好些年了——從分析師,到自己一人建過 warehouse 的數據工程師,再到帶團隊的數據主管。但我的工程規範,大多是「帶人」帶出來的:跟底下的 data engineer 過技術、吵規範,我清楚什麼是好 commit、什麼不該進版控;可是親手把這些規範焊進工具——設 hook、配 CI——那一直是工程師的事,不是我的肌肉記憶。
直到我用 Claude Code 自己 vibe coding,兩個多月建了一套每天自動更新的資料平台。一開始 AI 老犯同一種錯:忘記跑測試、commit 訊息亂寫、把不該進版控的檔案塞進去。我知道你在想什麼——這些 git hook、gitignore、gitleaks 早就能擋。沒錯。但我當下的本能不是「去設個 hook」,而是「把要求講清楚」,就像我以前帶人那樣:AI 忘東西,我就往 CLAUDE.md 多寫一條;又犯,再補一條。檔案越長,我越安心。
結果是反過來的。規則堆到一定程度,AI 開始忽略指令——包括那些我真正在乎的。後來我把其中一份規範檔從 93 行砍到 64 行,它反而更聽話了。
這篇是我邊做資料平台邊測出來的踩坑筆記——這套做法目前用起來最順手,但到底是不是最好,我也還在試。我想通的核心是這個:大家想把 CLAUDE.md 當成 AI 的護欄,拿它擋住所有壞行為。但真正能擋的護欄,是 hook、CI、deny-list 那些機制;CLAUDE.md 擋不住任何事,它比較像新工程師報到要先讀的協作規範——只負責告訴 AI 該怎麼跟你協作。把這兩件事分開,剩下的就都通了。
長度本身就是成本
先講一件多數人沒意識到的事——而且這不是我的個人偏好,是 Anthropic 官方的 Claude Code 最佳實踐白紙黑字寫的:CLAUDE.md 太長,Claude 會忽略一半,重要規則被雜訊淹沒,所以要「無情地砍」。官方還補了一句很關鍵的——如果 Claude 不靠那條指令也做對,就刪掉它,或把它轉成 hook。經驗值是控制在 300 行以內、最好遠低於 200 行,有人甚至壓到 60 行出頭。
背後的道理很簡單:AI 的指令額度是有限的。你每多塞一條瑣碎規定,就稀釋掉一點它對「真正重要那幾條」的注意力。臃腫的 CLAUDE.md 不是中性的——它會讓 Claude 開始忽略你的指令。
我原本以為規範檔越完整越好,把所有可能出錯的地方都寫下來等於買保險。錯了。文件越長,保的不是險,是讓最重要的紅線被淹沒。
官方甚至列了一張「該寫 / 不該寫」對照表。但與其抄表,不如看同一份 CLAUDE.md 砍前砍後的樣子。這是我資料平台那份「太長」的開發規範:
## 開發規範
- commit 訊息一律用 conventional commit 格式
- commit 前一定要跑測試,全部通過才能 push
- 絕對不要對 main 分支 force-push
- 不要 commit .env、任何 API key 或密碼
- 每次改完都要跑 linter 和 formatter
- 一律用 2 空格縮排、命名要有意義
- 寫乾淨、可讀、好維護的程式碼
- 業務邏輯只寫在 transform 層,抓資料的層抓完落地就停
- 寫入一律冪等,用 upsert,不要裸 INSERT
- 跑測試前先 source .env.test,否則會打到正式資料庫
砍完之後,剩下這三行:
## 架構與環境(Claude 從 code 看不出來的)
- 業務邏輯只寫在 transform 層;抓資料的層抓完落地就停
- 寫入一律冪等:用 upsert,不要裸 INSERT
- 跑測試前先 source .env.test,否則會打到正式資料庫
「很好」那份,就是「太長」那份的最後三行——其他全砍了。砍掉的不是 Claude 本來就會的(縮排、命名、寫乾淨的 code),就是該交給機制的(跑測試、force-push、別 commit 密鑰——這些 hook、CI、gitignore 都擋得住,後面細講)。留下來的三行,是 Claude 翻遍整個 repo 也猜不到的。哪些該砍、砍去哪,就是接下來兩段要拆的事。
你給了告示牌,它在走舊路
第二件反直覺的事:你寫進 CLAUDE.md 的禁令,往往擋不過 AI 在訓練時養成的習慣。
我學生成式 AI 時記住一個比喻。規則像路口的告示牌,提醒你「該往這邊走」;但模型的訓練資料裡,某些路徑早就被踩出一條深溝,它讀完你的告示牌,常常還是順著舊路走下去。
這解釋了我一直想不通的現象:為什麼我寫了「禁止這樣做」,AI 還是這樣做?因為一條禁令是一塊告示牌,而它訓練時看過的幾百萬個反例是那條深溝。你用一句話,對抗不了一條被踩深的路。
最好的例子就是 print()。我在 CLAUDE.md 白紙黑字寫過這條:
- logging:用 logger,不要用 print()
結果呢?AI 該 print() 還是 print()。因為這條規範只是一塊告示牌,沒有任何東西真的攔它;而它訓練時看過的 print() 有幾百萬次,那條溝太深了。
那怎麼辦?答案不是把禁令寫得更用力。真正的修正是下一段——有些規則根本不該靠「AI 記得」的文字來守,print() 正是這種。
把規則切成兩種:硬規則,和軟判斷
想通的那一刻,是我把規則分成了兩類。
第一類是「硬規則」——格式長怎樣、哪些指令危險、什麼一定要跑。commit 的格式、跑不跑測試、能不能 force-push、哪些檔案不進版控。這類規則有個共同點:它們是確定的,沒有模糊地帶,對就是對、錯就是錯。
硬規則不該寫進 CLAUDE.md,該外包給機制:
- commit 格式錯了 → git hook 直接擋下來
- 測試沒過 → CI 不讓你合併
- force-push、
rm -rf這種危險指令 → 加進 deny-list,AI 根本碰不到 - 不該進版控的檔案 → 寫進
.gitignore,AI 自己讀得到 - 跨專案共用的 commit 慣例 → 用
@import拉一份進來,不在每個 repo 重抄
開頭那個 print() 就是硬規則。我回頭去 pyproject.toml 開了 ruff 的 T20 規則(flake8-print),就這幾行:
[tool.ruff.lint]
select = ["E", "W", "F", "I", "UP", "T20"] # T20 = 禁 print/pprint
[tool.ruff.lint.per-file-ignores]
"scripts/**" = ["T20"] # 給人看的 CLI,print 本來就是要的
"tests/**" = ["T20"] # 測試 debug 用
往後 print() 一律被 lint 擋下、commit 都進不去。寫文件求 AI 記得「不用 print」沒用,一條 lint 規則就一勞永逸。
機制是確定性執行。它不靠 AI「記得」,它在 AI 犯錯的當下就攔截。把硬規則交給機制,等於把這部分的記憶負擔整個移出去——AI 忘不忘記都無所謂,因為它根本繞不過去。說穿了,別讓 AI 做 linter 的事:那種工作 linter 一瞬間做完,AI 又慢又貴還會出錯。
而這些機制——hook、CI、deny-list——才是真正的「護欄」。繁中圈講 AI 護欄,指的就是這種能即時攔截、把你擋在界外的東西。攔截的活本來就該機制幹,不是文件。多數人的誤會,就是把護欄的責任丟給 CLAUDE.md,逼一份文件去做攔截器的事。
我那份從 93 行砍到 64 行的規範檔,砍的全是硬規則:commit 格式、force-push 禁令、lint 提醒——外包給 hook 和 deny-list;不該進版控的清單——.gitignore 本來就有,刪掉;hook 的詳細說明——跟設定檔註解重複,收斂回設定檔。留下來的只有軟判斷。我每砍一行都問同一個問題:刪掉它,會讓 AI 犯錯嗎? 不會,就砍——後來才發現,這跟前面引的官方砍檔準則一字不差,我只是自己撞上了。
第二類是「軟判斷」——機制擋不了的東西。這才是 CLAUDE.md 該留的:它不是護欄,是規範——機制攔不住、只能靠脈絡決定的事,寫成字讓 AI 每次開工先讀,就像新工程師報到得先讀懂團隊怎麼協作。
還記得開頭砍剩的那三行嗎?業務邏輯擺哪層、寫入要不要冪等、測試先接哪個庫——那三行就是軟判斷。它們不是 code 裡讀得到的事實,是設計時才知道的決定:翻遍整個 repo 也找不到答案,所以只能靠你寫成字告訴它。
而判斷本身,又可以再切成兩種,這是我覺得最值得講的一層。
判斷再切兩種:不變量,和邊界
我那套資料平台的 root CLAUDE.md,常駐的內容只有兩種判斷。
一種是「跨層不變量」——不管在哪一層都必須成立的性質,約束的是「怎麼做才對」:
# 跨層不變量
- 寫入一律冪等:執行一次或多次,結果相同
- 核心邏輯決定性:同樣輸入永遠同樣輸出
- 衡量新鮮度用事件時間,不是抓取時間
這些規則垂直貫穿每一層,抓資料的層要守,後面做轉換的層一樣要守。
另一種是「跨層邊界」——把層與層切開的線,約束的是「什麼東西該放哪、哪一層不准做什麼」:
# 跨層邊界
- 業務邏輯只在轉換層;抓資料的層抓完落地就停
- 整個專案不對外開 API
這些是水平的分界。
一句話對比:不變量說「每一層都要 X」,邊界說「X 只能在這層、不能在那層」。
為什麼這兩種非留在 CLAUDE.md 不可?因為 AI 從 code 看不出來。它讀一段程式,推不出「這裡必須冪等」,也推不出「這段業務邏輯不該寫在這層」。這正是文件該守、機制守不住的東西。硬規則可以外包給 hook,軟判斷只能寫成字。
反過來看:當你沒有機制可以外包
我還有另一份 CLAUDE.md,管的不是 code,是我用 Markdown 當資料庫的個人作業系統。有趣的是,那一份幾乎整篇都是軟判斷——一堆「這種內容該寫進哪個資料夾」「這層不准放那類紀錄」的路由規則,幾乎沒有任何硬規則。
一開始我以為是我把它寫得比較好。後來才懂,不是。是因為一個純筆記的知識庫,沒有測試、沒有 lint、沒有 CI、沒有 hook——根本沒有機制可以外包。每一條都是機制擋不了的判斷,只能留在文件裡。
這恰好反向印證了整件事:CLAUDE.md 該不該瘦、能瘦多少,取決於你的專案有多少硬規則可以交給機制。工程 repo 硬規則多,所以瘦身空間大;知識庫幾乎全是軟判斷,所以天生就薄在硬規則、厚在軟判斷。文件的胖瘦不是風格問題,是你有沒有把該外包的外包掉。
你開發的,不只是 code
回頭看那坨手抄的 prompt——它是死的。規矩變了你得手動回去改,沒人幫你,它只會爛、只會肥。
CLAUDE.md 是活的。讀它的那個 AI,也能回頭幫你改它:每次踩到新坑、收掉一個 bug,我就讓 AI 把學到的那條沉澱進 rules,文件跟著專案一起長大。
所以用 AI 開發,你寫的從來不只是 code。你同時在開發「自己怎麼跟 AI 協作」這套規範——你的 context 本身就是一個要設計、要瘦身、永遠沒有完工的專案。
CLAUDE.md 是規範,不是護欄
退一步看,這跟帶一個初級工程師沒兩樣。
你不會為了怕他忘記存檔,在他螢幕周圍貼滿便利貼——你會幫他把編輯器設成自動存檔。便利貼貼太多,他連最重要那張都看不到了。硬規則的事交給自動化,你只需要把注意力放在他真正需要你的地方:軟判斷。
CLAUDE.md 也一樣。它不是你把所有焦慮一條條寫下來的許願池,也不是攔截 AI 的護欄——能擋行為的是機制,文件擋不住任何事。它是規範:把那些機制守不住、只能靠脈絡決定的判斷,凝固成一份 AI 每次開工都會讀的協作守則。
我不敢說 64 行就是終點——搞不好再過陣子,我又砍掉幾條、或加回幾條。但有個方向我越測越確定:硬規則,外包給機制。軟判斷,留在文件,而且分清楚是不變量還是邊界。當你的 CLAUDE.md 開始變長,先別急著再加一條,問問自己:這條,是機制該擋的硬規則,還是文件才守得住的軟判斷?
上面講的每條原則——硬規則外包、不變量、邊界、規範導覽、path-scoped 載入、@import、驗證指令——在我自己的 CLAUDE.md 裡都找得到對應。
先給整套的全貌——哪個檔負責什麼:
專案根/
├── CLAUDE.md ← 永遠載入:跨層不變量、邊界、核心原則
├── .claude/rules/
│ ├── sources-common.md ← 改任何資料來源都要守的共用規範
│ ├── <來源>.md ← 各來源專屬細則,碰到那個來源才載入
│ ├── orchestrator.md ← 排程與資料新鮮度規範
│ └── transform.md ← 轉換層(dbt)規範
└── src/sources/<來源>/CONTRACT.md ← 對下游的承諾:我輸出的資料長這樣
root 放的是每次都要守的判斷,其他全是 path-scoped——碰到對應檔案才載入。所以 AI 任何時候讀到的,都只是當下這件事該守的那幾條,不是整面牆的規矩。
照抄前先分清楚哪些動不得:CLAUDE.md 是 Claude Code 規定的固定檔名,改名它就不讀;path-scoped 規則一定要放進 .claude/rules/ 這個資料夾才認得,但裡面要叫 sources-common、transform 還是什麼,隨你取。至於 src/.../CONTRACT.md 那條,跟 Claude Code 無關,純粹是我自己的專案結構和命名慣例——你的專案長怎樣,就改成你的。
下面這份就是我那套資料平台實際在用的 root CLAUDE.md,完整去識別化(資料源名稱換成佔位符、私人路徑拿掉,結構一字不動),可以直接複製改路徑就用。
附錄:我實際在用的 CLAUDE.md(去識別化,可直接複製)
完整版放在下面,訂閱 kirolife 即可免費閱讀,順便收得到這個系列之後的更新。